Cada vez mais presentes nos mais diversos contextos, a visão computacional é a tecnologia que, através de câmeras e softwares de processamento de imagens, conseguem interpretá-las. Com isso, consegue inspecionar e detectar determinados elementos.
Somada ao machine learning, a tecnologia tem sido usada para análise de áreas de risco, inspeção de jogadores em campo e detecção de problemas em células em imagens microscópicas. Além disso, também pode ser usada para detecção de animais, movimentação de objetos em ambientes controlados, entre outras funções.
No entanto, em seu trabalho mais comum, a visão computacional é usada em reconhecimento de padrões, mostrando-se uma ferramenta poderosa e multiúso dentro da indústria. Para entender mais sobre como essa tecnologia é usada, como funciona e o que pode fazer, continue lendo este artigo.
O que é visão computacional?
A visão computacional pode interligar-se com a inteligência artificial, ainda que trabalhar com IA não seja um requisito para a existência de softwares de visão computacional. Assim, a tecnologia estuda o processamento de imagens, dando às máquinas a capacidade de fazer interpretações através das imagens.
Isso significa que essa tecnologia não apenas consegue capturar imagens, mas também distingui-las e agrupá-las em diferentes categorias previamente estipuladas.
Por exemplo, se você usa o Google Fotos, já viu que o aplicativo cria automaticamente pastas com imagens semelhantes, como “fotos de céu ensolarado” e “fotos de cachorros”.
O que é um software de visão computacional?
Softwares são instruções que são seguidas para que algo ocorra. De forma mais simplificada, pense em cada programa do seu celular ou computador como um software, em que se faz uso deles para que algo ocorra.
Assim, softwares com visão computacional são programas capazes de decifrar e interpretar imagens, trabalhando de forma semelhante ao olho humano.
Toda vez que você precisa verificar que não é um robô ao entrar em algum site e assinalar fotos em que aparecem faixas de pedestre, por exemplo, está lidando com um software com esta tecnologia.
Como funciona a visão computacional?
Para que um software consiga distinguir algo em uma imagem e classificá-la, ela passa por um sistema que inclui as seguintes etapas, na visão computacional clássica:
- Aquisição – o software realiza a captura das imagens.
- Processamento – momento em que podem ser aplicados filtros de diminuição de
ruído, rotação da imagem ou outros recursos para facilitar sua otimização.
- Análise – a partir do momento em que cada imagem ganha uma função, a máquina é capaz de visualizá-las com mais clareza, já que sabe com o que está lidando.
- Reconhecimento – é nessa fase que as imagens são classificadas por suas semelhanças, em que a máquina reconhece padrões.
Hoje, a visão computacional trabalha com outra etapa: o deep learning, processo que se situa entre a fase de análise e de reconhecimento, em que a máquina aprende com vários exemplos. Resumidamente, o computador é capaz de filtrar imagens, textos e sons em imagens, aprendendo a classificar mais informações.
Assim, a visão computacional clássica é pouco generalista, funcionando melhor com casos específicos, como em fábricas, com máquinas descartando peças com defeitos. Já com o deep learning, que permite a realização de atividades específicas de forma mais precisa, pode-se explorar seus diversos usos, classificando uma grande gama de informações.
Como é feito um software de visão computacional?
Criar um software de visão computacional envolve diversos outros conhecimentos, mas de forma geral, o programador precisa escolher o que será identificado nas fotos, ou seja, que tipo de problema será resolvido.
Assim, o responsável deve pensar em qual é a necessidade da aplicação do software de visão computacional. Casos com baixa diversidade de situações (como o exemplo de uma fábrica que precisa descartar produtos com defeito ou fora dos padrões) poderá alimentar a base de dados com cerca de 50 imagens.
No entanto, em casos mais genéricos, em que o software terá que analisar diversos fatores, o profissional poderá usar muito mais imagens, para que o computador aprenda a distinguir algo nos mais diversos cenários, com cores e iluminações diferentes.
Ou seja, a quantidade de imagens necessárias para a base de dados depende da aplicação do programa. Softwares que precisam identificar mais detalhes ou uma quantidade maior de informação precisam de mais dados, enquanto outros, de funcionamento mais simples, de menos dados na base.
Após criar um banco de imagens condizentes com as necessidades do software, ainda há algumas etapas antes de começar o treino. Confira-as a seguir.
1. Data Augmentation
Técnicas usadas para criar um aumento artificial no tamanho do conjunto de treinamento tendo como base os dados já existentes. É uma boa prática para evitar o excesso de dados ou mesmo para melhorar o resultado do modelo, editando as imagens existentes, usando rotações, efeito invertido, mudanças na saturação, claridade, entre outras técnicas.
2. Escolha do modelo
O próximo passo resume-se ao estado da arte, ou seja, mapeamento de todos os dados e estudos sobre o software. Com isso, escolhe-se seu modelo, levando em conta as redes neurais convolucionais (CNNs) e o algoritmo de deep learning que capta a imagem e atribui a ela importância.
Assim, o programador ou engenheiro escolherá a arquitetura das redes neurais que utilizará, bem como vários aspectos de métodos de processamento digital de imagens, considerando as diferenças de velocidade e precisão, bem como vantagens e desvantagens de cada modelo.
De acordo com a aplicação do software, há a necessidade de uma rede mais complexa ou menos complexa, correspondendo também ao orçamento do projeto.
3. Otimização de hiperparâmetros
Antes de treinar o modelo escolhido, é necessário encontrar o melhor hiperparâmetro. No processo de machine learning – forma de inteligência artificial que identifica padrões com pouca intervenção humana – os parâmetros influenciam na performance do algoritmo.
Por sua vez, os hiperparâmetros são as variáveis do algoritmo, definidas antes de se iniciar o treinamento. Após definir os parâmetros e hiperparâmetros, trabalhando em sua otimização, o software atingirá melhores resultados.
4. Avaliação durante o treino
Com todos os parâmetros alinhados, o engenheiro pode começar o treino do modelo, realizando um processo iterativo de otimização. No entanto, existem dois tópicos que requerem atenção: o underfitting e o overfitting.
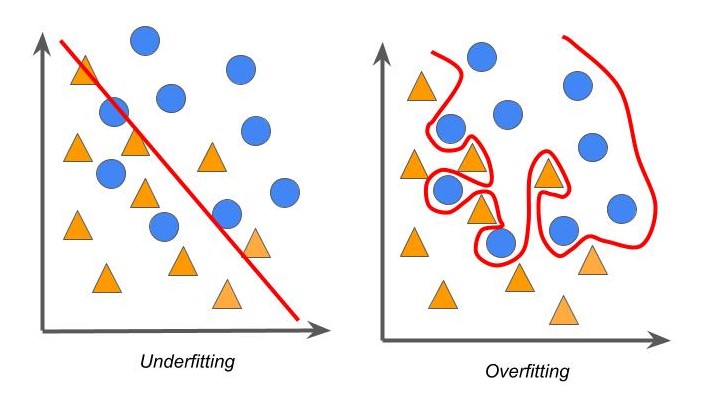
O underfitting refere-se ao modelo que não foi capaz de aprender o suficiente ou da forma correta. Isso pode acontecer por diversos fatores, como problemas nos dados, na arquitetura, parâmetros ou tempo de treino. Para corrigir o problema, é necessário uma avaliação dos resultados.
Por outro lado, o overfitting é o termo oposto, tão acostumado aos dados do treino que não é capaz de fazer generalizações de novas informações além daquelas usadas no treino. Nesse caso, também deve-se fazer uma avaliação para encontrar o erro e corrigi-lo, de forma a não ter nem um underfitting, nem overfitting, mas treinamento na medida certa.
5. Avaliação final
Depois de todos esses processos, de data augmentation, escolha do modelo, otimização de parâmetros e hiperparâmetros e avaliações durante o treino, o software passará pela avaliação final. Assim, o modelo será avaliado em um novo conjunto de dados (ou seja, informações diferentes do treinamento).
Com isso, o engenheiro saberá se o software é capaz ou não de fazer generalizações. Caso tudo esteja certo, poderá usar seu programa. Em caso negativo, deverá analisar novamente os passos anteriores a fim de corrigir eventuais problemas.
Para que servem os softwares de visão computacional?
Softwares de visão computacional são capazes de ajudar diversos negócios. Assim, ao serem implementados em empresas, podem reduzir seus custos ao automatizar algumas ações.
Além disso, ainda otimizam alguns processos, fazendo com que os trabalhos sejam feitos de forma mais precisa e rápida. Esses softwares ainda podem garantir a segurança de etapas e outras regiões de interesse nos mais diversos processos.
Entre outros serviços, os programas que se utilizam dessa tecnologia podem melhorar a experiência de clientes com uma empresa, aliando outros segmentos da inteligência artificial à visão computacional.
O que a visão computacional consegue fazer?
Diversos são os usos da visão computacional, que é capaz de classificar imagens por padrões e, com isso, detectar objetos. Além disso, também rastreia objetos em vídeos, trabalhando não somente com imagens estáticas, mas também com aquelas em movimento.
Ao desbloquear seu celular com o reconhecimento facial ou quando você tira uma foto segurando um documento para comprovar sua identidade, a visão computacional é a responsável por identificar um padrão entre as imagens e liberar o seu acesso.
Multas de trânsito são outro exemplo da aplicação dessa tecnologia, que identifica veículos e suas placas, ligando a imagem ao dono do carro, ou mesmo em fábricas, em que há a inspeção de qualidade nas linhas de produção.
Mas, além de trabalhar para empresas, a visão computacional ainda pode ajudar a vida de pessoas com deficiência visual, trazendo acessibilidade, porque os softwares descrevem imagens através de textos.
Estas são apenas algumas das aplicações da tecnologia, que tem crescido cada vez mais, ao passo que a inteligência artificial permite um treinamento customizado para cada aplicação.
Com isso, investir nessa tecnologia não é um luxo, mas uma forma de otimizar o trabalho de uma empresa, poupando tempo e fazendo um trabalho mais preciso.
Agora que você já sabe o que são softwares de visão computacional, como funcionam, o que podem fazer e como estão presentes na nossa rotina, pode querer implantá-los em sua empresa. Para isso, entre em contato com os profissionais da Apollo Solutions e compartilhe esse post com um amigo que pode gostar de conhecer essa tecnologia.